
Analysis Platforms
The ELITE Portal enables interoperability, allowing researchers to collaborate, share, and connect with data. Data from the portal can be used in several Trusted Research Environments (TRE).
Enabling integration between the ELITE Portal and TREs is another step toward a greater goal to provide seamless, secure access to biomedical datasets from the ELITE Portal in as many analytical and compute environments as possible.
How they fit together
-
ELITE Portal: the entryway to your governed data hub. Discover projects, cohorts, data, tools, and people through the ELITE Portal web interface.
-
Synapse: the data storage, organization, and governance infrastructure underlying the ELITE Portal.
-
CAVATICA: a storage, sharing, and analysis platform designed to handle large volumes of genomics data. It is produced in collaboration with Seven Bridges and based on the Seven Bridges Platform for cloud storage and bioinformatics analysis. CAVATICA supports team projects, notebooks (Jupyter/RStudio), and CWL workflows.
-
Terra.bio: an analysis platform for biomedical data analysis, secure sharing, and global collaboration. Terra.bio supports shareable workspaces, notebooks (Jupyter/RStudio/Galaxy), and WDL workflows.
-
AD Workbench: a secure, cloud-based data sharing and analytics environment offered by the AD Data Initiative. Easy to use and available at no cost, AD Workbench empowers researchers around the world to share, access and analyze data across platforms.
-
AD Discovery Portal: a user-friendly, publicly accessible dataset catalog designed to enable researchers to explore novel Alzheimer's disease data that are available via AD Workbench.
-
Quick-Start Guide
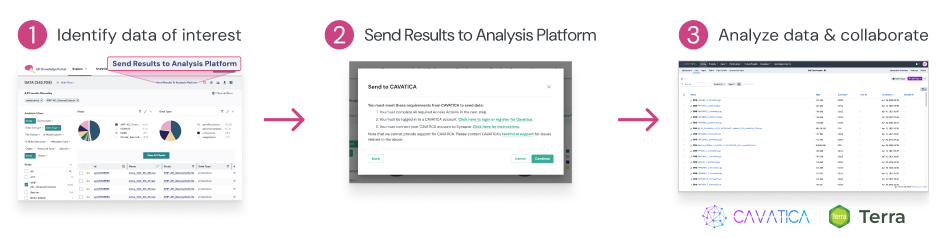
Discover from the Portal → Analyze in CAVATICA
-
Identify data of interest
-
Complete requirements for access, as applicable
-
Import into CAVATICA via GA4GH DRS (UI: “Add Files → DRS” or via API for bulk). Files are aliased, i.e., they stay where they live and CAVATICA references them.
-
Run tasks or pipelines against the aliased, DRS-linked files
Discover from the Portal → Analyze in Terra
-
Identify data of interest
-
Complete requirements for access, as applicable
-
Link accounts & hand off to Terra from the Portal
-
Bring data into a Terra workspace via DRS (works for notebooks or workflows)
-
Run interactive or batch analysis by launching Jupyter, RStudio, Galaxy or run WDL pipelines
Disclaimer: Sage Bionetworks may integrate with, and provide links to, compute environments as an alternative to downloading files. These integrations or provisions do not signify an endorsement of that particular environment by Sage Bionetworks or funders, nor does it alter the relationship between Sage Bionetworks, existing data contributors, project sponsors or funders, or computational providers.
Furthermore, it is the responsibility of individual users to review the terms of data use for each compute environment, as well as for the portal or repository from which the data is sourced. Users must personally ensure that all data access terms and conditions are met.